In the last month or two I’ve had basically the same conversation half a dozen times, both online and in real life, so I figured I’d just write up a blog post that I can refer to in the future.
The reason most high level languages are slow is usually because of two reasons:
- They don’t play well with the cache.
- They have to do expensive garbage collections
But really, both of these boil down to a single reason: the language heavily encourages too many allocations.
First, I’ll just state up front that for all of this I’m talking mostly about client-side applications. If you’re spending 99.9% of your time waiting on the network then it probably doesn’t matter how slow your language is – optimizing network is your main concern. I’m talking about applications where local execution speed is important.
I’m going to pick on C# as the specific example here for two reasons: the first is that it’s the high level language I use most often these days, and because if I used Java I’d get a bunch of C# fans telling me how it has value types and therefore doesn’t have these issues (this is wrong).
In the following I will be talking about what happens when you write idiomatic code. When you work “with the grain” of the language. When you write code in the style of the standard libraries and tutorials. I’m not very interested in ugly workarounds as “proof” that there’s no problem. Yes, you can sometimes fight the language to avoid a particular issue, but that doesn’t make the language unproblematic.
Cache costs review
First, let’s review the importance of playing well with the cache. Here’s a graph based on this data on memory latencies for Haswell:
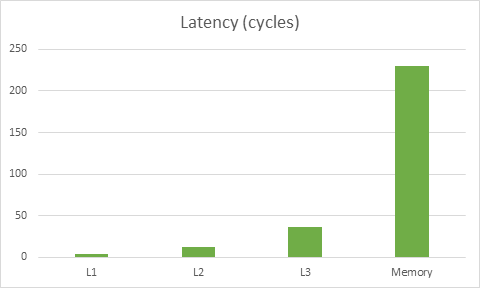
The latency for this particular CPU to get to memory is about 230 cycles, meanwhile the cost of reading data from L1 is 4 cycles. The key takeaway here is that doing the wrong thing for the cache can make code ~50x slower. In fact, it may be even worse than that – modern CPUs can often do multiple things at once so you could be loading stuff from L1 while operating on stuff that’s already in registers, thus hiding the L1 load cost partially or completely.
Without exaggerating we can say that aside from making reasonable algorithm choices, cache misses are the main thing you need to worry about for performance. Once you’re accessing data efficiently you can worry about fine tuning the actual operations you do. In comparison to cache misses, minor inefficiencies just don’t matter much.
This is actually good news for language designers! You don’t have to build the most efficient compiler on the planet, and you totally can get away with some extra overhead here and there for your abstractions (e.g. array bounds checking), all you need to do is make sure that your design makes it easy to write code that accesses data efficiently and programs in your language won’t have any problems running at speeds that are competitive with C.
Why C# introduces cache misses
To put it bluntly, C# is a language that simply isn’t designed to run efficiently with modern cache realities in mind. Again, I’m now talking about the limitations of the design and the “pressure” it puts on the programmer to do things in inefficient ways. Many of these things have theoretical workarounds that you could do at great inconvenience. I’m talking about idiomatic code, what the language “wants” you to do.
The basic problem with C# is that it has very poor support for value-based programming. Yes, it has structs which are values that are stored “embedded” where they are declared (e.g. on the stack, or inside another object). But there are a several big issues with structs that make them more of a band-aid than a solution.
- You have to declare your data types as struct up front – which means that if you ever need this type to exist as a heap allocation then all of them need to be heap allocations. You could make some kind of class-wrapper for your struct and forward all the members but it’s pretty painful. It would be better if classes and structs were declared the same way and could be used in both ways on a case-by-case basis. So when something can live on the stack you declare it as a value, and when it needs to be on the heap you declare it as an object. This is how C++ works, for example. You’re not encouraged to make everything into an object-type just because there’s a few things here and there that need them on the heap.
- Referencing values is extremely limited. You can pass values by reference to functions, but that’s about it. You can’t just grab a reference to an element in a List<int>, you have to store both a reference to the list and an index. You can’t grab a pointer to a stack-allocated value, or a value stored inside an object (or value). You can only copy them, unless you’re passing them to a function (by ref). This is all understandable, by the way. If type safety is a priority, it’s pretty difficult (though not imposible) to support flexible referencing of values while also guaranteeing type safety. The rationale behind these restrictions don’t change the fact that the restrictions are there, though.
- Fixed sized buffers don’t support custom types and also requires you to use an unsafe keyword.
- Limited “array slice” functionality. There’s an ArraySegment class, but it’s not really used by anyone, which means that in order to pass a range of elements from an array you have to create an IEnumerable, which means allocation (boxing). Even if the APIs accepted ArraySegment parameters it’s still not good enough – you can only use it for normal arrays, not for List<T>, not for stack-allocated arrays, etc.
The bottom line is that for all but very simple cases, the language pushes you very strongly towards heap allocations. If all your data is on the heap, it means that accessing it is likely to cause a cache misses (since you can’t decide how objects are organized in the heap). So while a C++ program poses few challenges to ensuring that data is organized in cache-efficient ways, C# typically encourages you to allocate each part of that data in a separate heap allocation. This means the programmers loses control over data layout, which means unnecessary cache misses are introduced and performance drops precipitously. It doesn’t matter that you can now compile C# programs natively ahead of time – improvement to code quality is a drop in the bucket compared to poor memory locality.
Plus, there’s storage overhead. Each reference is 8 bytes on a 64-bit machine, and each allocation has its own overhead in the form of various metadata. A heap full of tiny objects with lots of references everywhere has a lot of space overhead compared to a heap with very few large allocations where most data is just stored embedded within their owners at fixed offsets. Even if you don’t care about memory requirements, the fact that the heap is bloated with header words and references means that cache lines have more waste in them, this in turn means even more cache misses and reduced performance.
There are sometimes workarounds you can do, for example you can use structs and allocate them in a pool using a big List<T>. This allows you to e.g. traverse the pool and update all of the objects in-bulk, getting good locality. This does get pretty messy though, because now anything else wanting to refer to one of these objects have to have a reference to the pool as well as an index, and then keep doing array-indexing all over the place. For this reason, and the reasons above, it is significantly more painful to do this sort of stuff in C# than it is to do it in C++, because it’s just not something the language was designed to do. Furthermore, accessing a single element in the pool is now more expensive than just having an allocation per object – you now get two cache misses because you have to first dereference the pool itself (since it’s a class). Ok, so you can duplicate the functionality of List<T> in struct-form and avoid this extra cache miss and make things even uglier. I’ve written plenty of code just like this and it’s just extremely low level and error prone.
Finally, I want to point out that this isn’t just an issue for “hot spot” code. Idiomatically written C# code tends to have classes and references basically everywhere. This means that all over your code at relatively uniform frequency there are random multi-hundred cycle stalls, dwarfing the cost of surrounding operations. Yes there could be hotspots too, but after you’ve optimized them you’re left with a program that’s just uniformly slow. So unless you want to write all your code with memory pools and indices, effectively operating at a lower level of abstraction than even C++ does (and at that point, why bother with C#?), there’s not a ton you can do to avoid this issue.
Garbage Collection
I’m just going to assume in the following that you already understand why garbage collection is a performance problem in a lot of cases. That pausing randomly for many milliseconds just is usually unacceptable for anything with animation. I won’t linger on it and move on to explaining why the language design itself exacerbates this issue.
Because of the limitations when it comes to dealing with values, the language very strongly discourages you from using big chunky allocations consisting mostly of values embedded within other values (perhaps stored on the stack), pressuring you instead to use lots of small classes which have to be allocated on the heap. Roughly speaking, more allocations means more time spent collecting garbage.
There are benchmarks that show how C# or Java beat C++ in some particular case, because an allocator based on a GC can have decent throughput (cheap allocations, and you batch all the deallocations up). However, this isn’t a common real world scenario. It takes a huge amount of effort to write a C# program with the same low allocation rate that even a very naïve C++ program has, so those kinds of comparisons are really comparing a highly tuned managed program with a naïve native one. Once you spend the same amount of effort on the C++ program, you’d be miles ahead of C# again.
I’m relatively convinced that you could write a GC more suitable for high performance and low latency applications (e.g. an incremental GC where you spend a fixed amount of time per frame doing collection), but this is not enough on its own. At the end of the day the biggest issue with most high level languages is simply that the design encourages far too much garbage being created in the first place. If idiomatic C# allocated at the same low rate a C program does, the GC would pose far fewer problems for high performance applications. And if you did have an incremental GC to support soft real-time applications, you’ll probably need a write barrier for it – which, as cheap as it is, means that a language that encourages pointers will add a performance tax to the mutators.
Look at the base class library for .Net, allocations are everywhere! By my count the .Net Core Framework contains 19x more public classes than structs, so in order to use it you’re very much expected to do quite a lot of allocation. Even the creators of .Net couldn’t resist the siren call of the language design! I don’t know how to gather statistics on this, but using the base class library you quickly notice that it’s not just in their choice of value vs. object types where the allocation-happiness shines through. Even within this code there’s just a ton of allocations. Everything seems to be written with the assumption that allocations are cheap. Hell, you can’t even print an int without allocating! Let that sink in for a second. Even with a pre-sized StringBuilder you can’t stick an int in there without allocating using the standard library. That’s pretty silly if you ask me.
This isn’t just in the standard library. Other C# libraries follow suit. Even Unity (a game engine, presumably caring more than average about performance issues) has APIs all over the place that return allocated objects (or arrays) or force the caller to allocate to call them. For example, by returning an array from GetComponents, they’re forcing an array allocation just to see what components are on a GameObject. There are a number of alternative APIs they could’ve chosen, but going with the grain of the language means allocations. The Unity folks wrote “Good C#”, it’s just bad for performance.
Closing remarks
If you’re designing a new language, please consider efficiency up front. It’s not something a “Sufficiently Smart Compiler” can fix after you’ve already made it impossible. Yes, it’s hard to do type safety without a garbage collector. Yes, it’s harder to do garbage collection when you don’t have uniform representation for data. Yes, it’s hard to reason about scoping rules when you can have pointers to random values. Yes, there are tons of problems to figure out here, but isn’t figuring those problems out what language design is supposed to be? Why make another minor iteration of languages that were already designed in the 1960s?
Even if you can’t fix all these issues, maybe you can get most of the way there? Maybe use region types (a la Rust) to ensure safety. Or maybe even consider abandoning “type safety at all costs” in favor of more runtime checks (if they don’t cause extra cache misses, they don’t really matter… and in fact C# already does similar things, see covariant arrays which are strictly speaking a type system violation, and leads to a runtime exception).
The bottom line is that if you want to be an alternative to C++ for high performance scenarios, you need to worry about data layout and locality.

It can be done better, if people care https://github.com/Microsoft/Microsoft.IO.RecyclableMemoryStream
Thanks, that’s a great post! I share most of your remarks and I agree that data layout and locality is the the main performance bottleneck for a high level language like C# (solution like .NET Native address code gen quality which is a good thing, but not enough to close the gap).
Still, I believe that most of the things we are looking for can be added to the C# language and runtime without messing too much the language/runtime: There are many areas where this is possible:
– Object to Stack allocation promotion: with a `transient` keyword for marking method parameters that cannot store such references and an explicit stackalloc that works on class (and not only on fixed arrays as it is today), It would require some minor changes to the Roslyn Compiler and IL to store the information. For the runtime, It would require to adapt the stackmaps and let the GC visit their content as well.
– Fat/Embed object allocation (embed the allocation of an object inside another object): As you pointed out, the fixed keyword is very limited today. It is perfectly possible to support it. The changes are pretty similar to the Object to Stack promotion. Implementation would vary depending whether the inner object is referencable from the outside of the object (It is requiring some changes to the GC object header to support address backtracking to the root object)
– Support for single ownership object where allocation and de-alloc is completely deterministic.
– Use an immix “region-based” memory layout for the GC allocated blocks. This would allow to allocate different object to some specific block, by allowing to switch to a different immix block at runtime (it is just a switch in the TLS), but It would keep still leverage on the GC to coordinate everything (while immix still requires to track references to object inside blocks, it is fast to test if a block is completely free)
– With such a design (more explicit control on regions), I’m not entirely convinced that we would still need the combination of a GC with an MS + SS (Mark&Sweep + Semi-Space) to handle efficiently generations. That would mean that we would no longer have objects that can be moved by the GC, so more opportunities to allow unsafe operation on pointers on managed objects without pinning. Also, currently, the object header in .NET is quite cluttered by the need to store the hashcode – by direct value or via an index – as the object can be moved, we are loosing lots of precious bits in the object header that could be used to store additional infos – like the offset fat/embed object back-reference to root object or a bit to mark single-ownership objects…
– I would not mind to have some double “unsafe unsafe” region in the code where the runtime would remove some checks (arrays bounds… etc.)
These changes would allow much more opportunities for better locality and data layout. It would be still lots of work to bring it to C# (I’m not very familiar with GC CoreCLR but the Immix part would be quite a big change for it), but now that C#/.NET is much more open-source, there is more chance for us to help to work on this kind of changes.
“I’ve written plenty of code just like this and it’s just extremely low level and error prone.”
That’s the thing. C# may not be the best language for performance, but syntax-wise it is beautiful compared to other languages!
It’s ok if you don’t try to go against the grain of the language, which means you get slow code.
If you DO want to get around the and performance issues of C# (Java), this guy is pretty interesting http://mechanical-sympathy.blogspot.se/
Good points (ad I have blogged multiple times about similar). That being said, characterizations such as “slow” without reference to a performance specification are meaningless.
I do a large amount of real-time and near real-time (aka low latency) work. There are techniques (that only very rarely involve “unsafe”) which can make a major difference – IF the operational specifications dictate.
As a side note, I have a challenge that I have been offering for almost a decade. If there is a hard specification for performance for a Windows Application (i.e. user mode) that u can meet using another language, I can meet it with C#….so far I have not had to admit a loss…..
While nothing you say is incorrect, I think it’s unfair to compare a language like C# to C++ or C. Much like comparing a Dentist vs. a Doctor and complaining that the Dentist is not designed for heart transplants. Or a Ferrari vs. a Prius, stating the Prius isn’t efficiently designed for racing.
The point of C# is to make programming simple. From my experience you can nearly write any Business Level application in half the time as C++. Memory management can be completely ignored for the most part, and at worst, you dabble in multi-threading. Even then though, they have hand holders like the Background Worker, and compiler errors to prevent obvious invalid cross-threading. With the new JIT compiler, 4.3 beta / 4.6 / 5.0, whatever they call it, they have seriously improved GC, Multi-threading, Memory Management in general, and performance optimizations. I believe it’s the RyuJit project.
The age old monicker is that you pick the right tool for the right job, and as always, it’s simplicity vs. efficiency.
My point is exactly that – C# simply isn’t designed to run fast on modern CPUs, and I lay out why. You’d be surprised how often people suggest that C# is perfectly fine for writing performance sensitive code.
Your argument basically boils down to “let’s go back to living in caves and writing assembler because it’s fast”. Strangely, 99.99999% of people who use C# don’t have a problem with its performance. The tiny minority that does is either doing something wrong, or they write their code in low-level languages and deal with the cancer of manual memory allocation. They also don’t write blog posts that complain that high-level languages are slow *because they are high-level languages*.
I suggest you read my post again, because that’s very far from what my argument “boils down to”. My post simply examines why C# is slow if you write code idiomatically. If you’re fine with slow code (as many people are, which I acknowledge in the first section) then it’s obviously not going to be interesting to you.
If manual memory management is cancer, what is manual file management, manual database connectivity, manual texture management, etc.? C# may have “saved” the world from the “horrors” of memory management, but it introduced null reference landmines and took away our beautiful deterministic C++ destructors.
I’ve wondered for a long time now if high level languages are a good thing or not. I started programming with VB in the early 2000’s and I feel like it created a lot of bad habits. Besides the obvious performance issues in you address in your article, you could argue that just as problematic is how reliant programmers can become on things like automated garbage collection, etc… For about 5 years I had no idea what a pointer was. I was able to write “business apps” just fine without knowing that because most modern computers are insanely overpowered when it comes to running your average small business app. I wonder what happens to those programmers when they’re given a project on a much larger scale, though. Looking at it now, fundamentally understanding how a computer works is a huge part of what programming is, and high level languages often obfuscate that.
Regarding garbage collection, this is why Xojo (http://www.xojo.com) has always used reference counting. Apple has recently moved away from garbage collection as well and is pushing reference counting. Yes, referencing counting can result in memory leaks (if you’re not careful) but at least the developer can do something about that. In terms of performance, our current compiler is not an optimizing one. However, we are in the process of moving the backend of our compiler chain to LLVM which is an optimizing compiler. In our tests we have seen dramatic performance improvements. I think once we have completed that transition, we may very well have a high level language that plays well with the cache. But at the very least we certainly don’t suffer from the garbage collection issue.
Reference counting cannot scale to many cores (because of atomic instructions).
That’s true for naive ref counting. There are versions of ref counting that reduce the need for multi-core synchronization. I don’t know if Apple has any plans to do that sort of stuff (e.g. use non-atomic refcounts for objects that don’t transfer to other threads, coalesce/defer ref counting, ignore stack ref counts and do a quick stack scan periodically, etc.).
In a huge selection of domains, time-to-market trumps performance considerations. I believe all of Facebook was originally written in PHP, and then they swapped in C++ (and Java and D) for the backend as performance needs dictated. Youtube started on Python. Reddit runs on Python. WordPress runs 23% of the top million sites on the web and it’s written in PHP. Twitter launched with Ruby on Rails.
So I think focus on performance first is poor planning. Pick a productive language, and get your application working first. Then benchmark it and start replacing the slowest components with foreign function calls into C/C++/D/Rust/Nim/whatever.
“If you’re designing a new language”
Well, I’m doing one. Of course, now is just a toy. The idea is build a relational language for data oriented programming/apps, so where the relations (aka: tables) are values.. so a lot of use of values, struct/records, functions… not OO.
I’m doing this on F#. What to do to improve things? What to do to make a performant language, ie: more specific samples?
OTOH, garbage collection, while unacceptable for real-time applications, or any application having hard scheduling constraints, in fact reduces the time spent on memory management considerably. What’s more, with a proper coding style, you can avoid frequent creation and destruction of objects in high level languages too. Have a look at what these guys did (in Java – I know too little about .Net, but I suppose many things are similar): http://martinfowler.com/articles/lmax.html
I totally agree with you. The only thing I noticed was that whenever you said “type safety” you probably meant “memory safety”.
How about .NET Native? That should have significant performance increases. I just found out about this, so don’t know any pluses or minuses which may/may not exist
https://msdn.microsoft.com/en-us/library/dn584397%28v=vs.110%29.aspx
I mentioned it in the post. It will probably help for tight loops and the like, but it doesn’t affect data layout (at least not much). If you’re writing the type of program that spends a big chunk of its time in a tight loop that doesn’t have any cache misses anyway it’ll help, in general the cache misses will still happen and they’re so much more expensive than any instruction you can run that it’s still an issue.
It does help for load times though, obviously, since it cuts the JIT out of the loop.
🙂 … maybe contribute some of these ideas to the coreclr GC https://github.com/dotnet/coreclr/tree/master/src/gc
Great post – and really in-depth explanation.
Yes – C# and C++ are different beasts and productivity vs. performance is a trade-off, though people who think C++ is “cave-man language” should look at C++11/14. C++ has evolved to be more productive, while C# has not evolved to be more performant.
C++ is an outstanding language but it has two problems. The first problem with C++ is the same as the problem with Perl – if you restrict yourself to a narrow subset of the language and use recommended practices, your code will be awesome. But in both cases, the language is huge and lends itself to obfuscated code. So you can run into someone else’s valid, battle tested, production quality code and have no idea what it does.
Again, I’m not asserting that all C++ code is bad or most C++ code is bad, or that idiomatic C++ is difficult to read. This pain point is just a relic of the fact that the language has evolved a lot and supports a multiverse of paradigms.
The second problem is the slow feedback loop. C++ compiles slowly, it can’t be avoided because of the preprocessor and complex syntax. I think if you spend a lot of time working with scripting languages, a slow compilation process will drive you bonkers. Python code might run literally 200 times slower than equivalent C++ code, but by the time I’ve compiled – even just incrementally compiled – and run my C++ application 200 times I’ve run 2000 iterations of the Python version.
Automatic Reference Counting (ARC) is awesome. It’s like GC without the GC, and it’s used by Objective-C to great success. Other languages should try it on for size.
Oh, Swift uses it too.
https://en.wikipedia.org/wiki/Automatic_Reference_Counting
C++11 also offers automatic reference counting, through the shared_ptr (and weak_ptr) classes.
Between those, unique_ptr (for when you need automatic destruction but no ref counting because you’re not sharing the object between multiple users) and using the RAII pattern wherever possible, the only times I ever get to debug memory management issues is when I deliberately eschew those mechanisms for optimization purpose.
On the other hand, the last time I heard an horror story about tracking down memory leaks, it was from a friend working on a framework used to build industrial test benches software… In .net. It turns out that even with a gc, if you’re making something that runs 24/7 while acquiring and processing large amounts of data, your memory usage can easily balloon up faster than the gc can deal with it, and the heuristics and assumptions it uses to guess what to free and when may be unsuited to your particular usage. In that case you end up having to find out how to massage your code in a way where the GC will do what you need it to do.
So the magical system designed to make you not worry about memory management can easily end up forcing you to worry about it in an even more complicated fashion than with languages not using GCs.
@Zlodo:
> C++11 also offers automatic reference counting, through the shared_ptr (and weak_ptr) classes.
I don’t think those are quite the same as ARC. ARC is built into the compiler, and it doesn’t require the use of any special classes, it works on all Objective-C and Swift objects.
shared_ptr and co are template classes that can point to any type/class, which don’t need to be aware that they are used through a smart pointer or to provide any special implementation.
Think of it as a special pointer notation: you declare shared_ptr pSomething; instead of foo* pSomething. The reference counting and object deletion are automatic but the utilization of a shared_ptr instead of a plain C pointer is explicit.
A very clear post.
I like Rust’s approach, if I really needed to write fast code today (which I don’t; C#, its GC and its cache misses are fine for my current needs), I would try Rust instead of trying to go back to C++, to me its seems like the nearest thing to a C++ replacement. Do you think that could happen?
I’m not sure that lack of value semantics and heap allocation are necessarily the evils that are holding back higher level languages. Efficient runtimes in high level languages already use SSA & escape analysis to avoid heap allocations where you’d otherwise think they’d be. Heap allocators work very differently in GC’d languages, such that what heap allocations occur much more closely resemble stack allocations (they are linear, and tend to exhibit cache locality wins), and when they don’t, it is much easier to move around memory to improve locality *after* initial allocation. Similarly, even when references are needed, they aren’t *necessarily* quite as big in higher level languages as zero-based oops or compressed oops allow the runtime to cheat on their size.
While high level languages encourage spreading out code across a lot more classes/methods/libraries, because their linking is not built off of the C linker, they have dynamic binding and that has an amortized abstraction cost of zero. There’s a lot of work done to inline and optimize code in manner that is thoughtful about memory/cache architecture. The only issue is that it is generic, with limited insight from the programmer to inform on how to smartly manage memory. While that is an undeniable advantage, I think this essay way overstates how much the use of the heap and reference semantics necessarily contribute to relative inefficiencies in higher level languages.
It’s borne out by Java code in a number of environments that compete effectively with C++ & Fortran, with minimal hackery. Sure, you need to pay attention to performance to get good results, but that’s a universal maxim, regardless of what language you use.
Escape analysis acts on a tiny fraction of the problem domain. Storing stuff on the stack is awesome, but you’re obviously never going to store everything on the stack. The key is that your heap allocations are big, bulky and rare, rather than full of pointers with very little actual data and numerous. Escape analysis won’t detect that you really meant for this List to be “owned” by this FooBar and therefore embed it inside.
I don’t know of any GC that uses statistics to improve memory locality – it can remove holes, which helps if win the lottery, but it’ll never do as well as a programmer who spends a few minutes up front designing the data layout. For that to happen the language must support using values in a much more flexible way.
Yes, escape analysis won’t detect that you really mean that a list needs to be owned by FooBar, but in C++ said list would be built off of heap allocations that aren’t necessarily local to FooBar anyway. Further, in Java, for example, with an ArrayList, you’d have that list built off a single allocation of a big chunk of memory, and that memory would be local to FooBar. Most high level system languages have support for packing primitives, strings and arrays together in memory, and a developer spending “a few minutes up front designing the data layout” can therefore have plenty of impact (perhaps not as much as with C++, but enough to make the differences not nearly as much of a problem). To the extent it doesn’t happen, eden space will end up merging the memory together before it escapes out in to other generations. The JIT is also in a position to exploit the heck out of it.
Any linear allocator (which most high performance GC’s use) will inherently exploit locality of creation, and, as an example, the G1 compactor does move together bits of memory that tend to have matching access patterns. In general, the impact of various GC strategies on locality is an area that has been studied for decades.
As I said, there is no question that a developer’s knowledge of application behaviour allows for the achievement of better results, and no doubt “spending a few minutes up front designing the data layout” will often yield better results with C++ than with higher level languages. But I haven’t observed that such an approach would routinely trounce what a programmer in a high level language can accomplish with the same process, and in the latter case the impact of deferring that work until later might not be quite as significant. The big wins in C++ tend to come from much more significant changes to how you’d write your code.
Yes, the list might have an allocation inside, but that’s one allocation instead of two, and all the meta data (such as the length) is immediately available. Do you have any link showing me that ArrayList is one allocation? Because that strikes me as *highly* unlikely. If that was the case every time the list grows you’d need to find every single pointer referring to it and relocate them. That’s going to be way more expensive than doing the normal thing and having the “header data” separate form the actual elements. The difference being that in Java and C# that header object would have to be its own allocation.
Also, I feel like you’re missing the point here. This isn’t just for lists, it’s for everything. In C++ (and Rust, and others) the *default* is that objects are just stored “in line”, so having to go through a pointer to access a data member is pretty rare. Escape analysis simply can’t do this for you. You can sometimes pack data together manually and write horrible code for accessing it, but the whole point I’m making here is that Java/C# etc. make it difficult and clunky to get efficient code, whereas C++ doesn’t, and that’s the main reason why your average C# program runs much slower than your average C++ program.
An ArrayList in Java works much as it does with C++’s STL. If you provide an initial capacity at initialization time, the list will be pre-sized. Sure, when the list grows, you will have a reallocation at some point… much like you would with C++.
And yes, the header data is allocated separate from the array… much as with std::vector. If you use a LinkedList, the allocation strategy mirrors what you’d have with an std::list.
The point is that with an std::vector the “header” is stored embedded instead of in its own allocation. This is true for probably 90+% data members in C++, whereas it’s only true for a tiny fraction of members in Java and C#. Again, not just for lists and vectors: If the object doesn’t have any inherent need for dynamic size then in C++ there’s no allocation at all, whereas in Java there’s at least one, and usually many more (depending on how big the “subgraph” of that objet is).
From my personal experience multiple allocations kill time in C++, C# and Java. Just out of curiosity I recently ported highly optimized code from C++ to C#. Performance difference was <3% which was pretty much within margin of an error. Memory usage was also very similar. I expected at least 10-25% slower performance in C# with 2-3 times more memory usage but I was wrong.
Previously that same C++ code was running 6-7 times slower due to high number of small object allocations and deallocations.
With all that in mind I would only care about the unnecessary allocations and deallocations that are eating time. It also does not matter if language is C++ or C# as long as developer knows what is going on and does not waste time and memory by creating multiple small objects that are used only once and then discarded. Optimizing for L1 or L2 cache is just ridiculous.
> Optimizing for L1 or L2 cache is just ridiculous.
Not if you care about things running fast! There are very few things on a CPU that can make things go an order of magnitude slower, caches misses are one of them. I’ll concede that there are domains where high performance isn’t as important, but talk to some game developers what they do (hint, it’s all about cache misses: http://gdcvault.com/play/1021866/Code-Clinic-2015-How-to ).
> The point is that with an std::vector the “header” is stored embedded instead of in its own allocation. This is true for probably 90+% data members in C++, whereas it’s only true for a tiny fraction of members in Java and C#.
As you pointed out, it’d actually be disadvantageous for the header and the actual collection to be bound to the same allocation in C++, and it is not actually how std::vector works. There is an optimization for small string allocations in some implementations of std::string, but otherwise the general case is for the elements of an STL collection to be allocated separately from the header… That’s why std::vector::~vector needs to be more than the default destructor. If you look at std::vector in libstdc++’s std::vector, it has explicit calls out to _M_create_storage(size_t) which already tells you that said allocations are separate from the allocation of the vector headers.
An std::list node, at least in libstdc++, has a next and prev member, just like every other doubly linked list ine very other language, and you pay that overhead regardless of allocation patterns, and the only result you might hope for is that next & prev were allocated at one time.
> If the object doesn’t have any inherent need for dynamic size then in C++ there’s no allocation at all, whereas in Java there’s at least one, and usually many more (depending on how big the “subgraph” of that objet is).
Not at all. In C++, and object of:
struct Foo {
std::scoped_ptr b;
};
Will have b allocated separately, and in Java:
struct Foo {
int b;
};
Will not have b allocate separately. The semantics, more than the language, dominate the allocation pattern. C++ avoids the dynamic allocation *only* when there is a fixed sized known, prior to allocation, and often, even not then.
std::vector b;
Involved allocating for b, but also triggers a *separate* call to std::allocator for allocating 42 elements… just like you’d expect from the following Java code:
java.util.ArrayList b(42);
Take a look at stl_list.h in stdlibc++, the constructor for the list eventually calls _M_default_initialize(size_t), which performs the separate allocation. Same goes for std::vector. There’s a reason they go with that approach.
You’re not reading what I’m saying. I’ll try one last time: In C++ the header object for a vector is not allocated, it’s store “embedded” within the owner (the stack, or another object). In Java, the header object is allocated and you have to jump through a reference to access e.g. the length of the array. In both cases the actual array is allocated (because it’s dynamically sized). Thus, in the typical case C++ has one allocation for an std::vector (the array), whereas Java has two for an ArrayList (the array and the header). The delta is much higher for most classes IME (a fixed size C++ class has zero allocations, a fixed sized Java class needs at least one allocation and usually more, since all non-native members are allocations).
I’m not at all interested in the rest of your arguments. As I mentioned several times in the post, the interesting thing is what idiomatic code does, what the language pressures you into doing, not that it’s theoretically possible to do the opposite of what the language wants you to do.
Also, you seem pretty confused about C++ semantics. That vector example will *not* allocate twice. It creates the object “in-line” (e.g. on the stack) and only allocates the actual array. Java allocates both.
“That vector example will *not* allocate twice. It creates the object “in-line” (e.g. on the stack) and only allocates the actual array. Java allocates both.”
“That vector example will *not* allocate twice. It creates the object “in-line” (e.g. on the stack) and only allocates the actual array. Java allocates both. “
“That vector example will *not* allocate twice. It creates the object “in-line” (e.g. on the stack) and only allocates the actual array. Java allocates both.” Allocating on the stack is still allocating. As I mentioned, allocating on the heap in Java is remarkably like a C++ stack allocation (of course, what happens *after* allocation is very different) in terms of behaviour and relative complexity, so this isn’t just semantics (actually, depending on how the escape analysis goes, it can be *exactly* like a stack allocation). The Java ArrayList is actually much more likely to have both the object and at least the initial array allocated in a contiguous chunk of memory (if there is a resize, automatic memory management might eventually move the array memory adjacent to the object, but don’t hold your breath). That will often make the overhead of having to jump through the reference much lower than with std::vector (and the Java runtime is in a good position to use SSO-like tricks to avoid a real reference to the array).
Heap memory allocations using a free list (C++) or a linear garbage collector (C#) are apple and pears comparisons (and these kinds of comparisons have been done for decades).
When allocating in a language with a linear GC the only operation being done is increment heap pointer, while in C++ it involves traversing a free list to find a free spot on the heap. Therefore an an ArrayList allocation in C# even it has two allocations will only mean two heap pointer increases, one for the header object and one for the array. This also means you get cache locality almost for free for all newly allocated objects (even if they are in the heap)
For allocations memory managed languages like C# are usually faster than idiomatic C++ (excluding templated allocators and other strategies). Deallocation on the other hand is a different story, garbage collection can consume significant CPU cycles, but so can free list management in C++.
Another thing is in C# allocations are not locked operations, therefore multiple threads can allocate concurrently and usually there are multiple heap sections where the GC can collect and compact in the background, meaning you take advantage of spare cores in the machine while not slowing down your compute threads. Lock free concurrent allocations is not something easy to achieve in C++ although there are libraries that do this they have different characteristics than the standard ones.
In the end there’s no inherent ‘reason’ why you can’t make a C# program fast (very fast). Microsoft has rewritten the C# compiler from optimized C++ (it was a target to be very fast so C++ was used initially) to optimized C# and the results have shown that the new C# compiler is faster than the C++ one, however they have invested significantly to achieve this. You can read about it here:
http://mattwarren.org/2014/06/10/roslyn-code-base-performance-lessons-part-2/
Very good post.
We’re building a C# to C++ converter (www.blitworks.com/unsharper) primarily oriented for game code, so our experience is limited to a very specific area of all possible C# programs. What we’re observing is a notable speedup in the converted code (in the order of 2x-3x), which means we’re dealing with CPU bound code that most of the time is well cached, hence the speedup. The memory layout is basically the same as we’re replicating the heap and stack allocs, so removing bounds checking and all the optimizations that a C++ compiler can do, is really paying off in our case. Hopefully we can show some numbers and explain with much more detail our results in the coming future.
For the memory management we’re relying on reference counting, because, as you said, GC pauses are unacceptable for games (amongst other apps). The effort of hunting down circular references is well worth the gain of smooth animation, and in the kind of code we normally deal with, the theoretical disadvantage in efficiency of reference counting is not really noticeable.
Your article really helped me to appreciate the nuances of the differences between C# vs Rust vs C++ and where they are positioned on the spectrum. Thanks. I would be interested in how idiomatic code in Apple’s new Swift language fits in here given its lack of Garbage Collection.
Just use Lua: the interpreter is about a 100Kb which will have plenty of headroom in an 8MB L3 cache or even in the 256KB L2 cache 😉
With recent developments in unikernels your whole VM might fit in 6MB.
(look for minios)
More seriously:
Languages are there to help the programmer to convey his thoughts into code.
Writing administrative business applications in C++ is a waste of time.
Writing embedded applications in .Net, Java or any other high level language is a waste of joules.
I’d say pick the right tool for the job.
I guess all those Unity3d games that are making millions on the Apple and Google stores are doing something wrong.
First off, the fact that something is popular doesn’t mean it’s the right choice. Secondly, I’ve talked to a lot of developers of high-end Unity games (i.e. where they care about solid framerate), and in fact my day job is largely to optimize Unity projects, and they spend a TON of time doing all the horrible things you have to do to work around these issues. They’re NOT writing high level and pretty C#. If you’re writing a simpel 2D game with limited animation and you don’t care about dropping frames, then you by definition don’t care about the language being slow and there’s nothing preventing those kinds of apps from making money. It’s when you do care about things being fast that you should be aware that you’re starting off with a big handicap that you’ll end up paying for one way or another later on (either by having a sluggish game that stutters all the time, or by spending a ton of time up front avoiding the issues, or by spending a ton of time fixing it after it’s already an issue).
Having worked on multiple C++ projects that were extended and maintained for many many years I have to say that C++ projects start with usual “let’s do it in C++ because we can optimize it”. However, after years of development, extensions and maintenance C++ code becomes much uglier than anything else that could be developed in higher level language. Not only C++ code is uglier but it is also very difficult to extend and any significant refactoring is close to impossible. In the end we have C++ code that theoretically could be optimized up to machine level and CPU caching but in practice runs slower than C# or Java code could and is less maintainable.
I’ve seen plenty of C# code that’s ugly and unmaintainable too. In fact, if you do need performance the C# you write is much uglier and messier than idiomatic C# or C++.
It’s kind of a different blog topic, but the whole OOP way of writing code has a high chance of leading to a nightmare of tangled messes. Keeping things simpler (closer to C) even in high level languages pay off (easier to read, easier to optimize, easier to change).
While language design has a role to play in making sure your code can evolve cleanly, I don’t think C# or Java has any major advantage over C++ there. Either way you’re fighting an uphill battle to keep entropy under control, and if you don’t making any kind of changes later is hard.
As some people say you can do Visual Basic programming in any language but there are too many huge disadvantages that C++ has. Standard libraries are crap. Collections are pathetic. Refactoring tools are miserable. That leads to the code that gets crappy much much faster.
From business perspective C++ is close to dead. There are very very few places where it makes sense and the sad part is that language itself could be saved by decent standard library but it could be too late. The smartest people are gone. Only sheldons now use C++
@Pau: “Collections are pathetic”.
Could you elaborate, please?
One problem is difference between language supported collections and libraries. Language itself has only array as built-in collection type. This type has no bounds checking and it cannot be used as an object. There is no way to figure out how many elements are in array if one has only pointer to array. There are no iterators/enumerators for arrays so in C++ we have only syntactically obfuscated pointer arithmetic.
Now if we go to STL collections get a bit better but still due to language separation of pointers and values we cannot simply have a vector of objects. One has to think if that vector has to have bunch of pointers that must be deleted manually or full objects that require copy constructors, assignment operators and other considerations related to vector resizing. Everything could be done using smart pointers or ref counted ones but that is one more extra level of indirection which looks ugly and could be hard to maintain. Sometimes there is a need to change from value objects to pointers when objects become too big. In C++ that may require significant re-design of the program. In C#/Java such problem just does not exist.
Finally LINQ in C# blows C++ out of water. Where C++ programmer can spend days working on data retrieval and sorting in C# stuff can be done in a few hours.
I think @Pau you are either grossly overstating things, or your frustration with the language comes from a lack of understanding. C++’s arrays are from C, and are often used as a building block for collections, much as in Java & C#, and std::array is every bit as much of a collection… in fact more so than Java & C# arrays. C++ arrays have sizes, but yes, you can hide that size information with a pointer/iterator… a very useful encapsulation technique that you see in most programming languages.
STL is as much a part of C++ as much as the Java standard library or the C# standard library is. Strip away their standard libraries, and all of the languages have little to offer in the way of collections or pretty much anything else you’d expect in a language.
A collection of reference types in C# or Java, already has the overhead you are complaining about with a C++ collection of smart pointers or Pimpl’s. You can use pointer containers if you’d rather manage it all cleanly. Any of those approaches is exactly how you do a collection of runtime polymorphic objects, and again… it imposes no more overhead than you already have in C# or Java. Switching between value and reference semantics is pretty jarring (and usually is about a lot more than just performance), but doesn’t require a “significant rewrite”… that’s one of the powerful aspects of C++’s templates over generics in Java & C# (in fact, because C# locks in reference or value semantics at type declaration and Java only allows value semantics for some of its built in types, it’s a much bigger rewrite in either of those languages). Oh and LINQ, lovely as it is, has implementations in C++. Even without them, there are plenty of other ORM libraries (say like ODB, which to your other point: “allows you to seamlessly use value types, containers, and smart pointers” with the same codebase) that make light work of data retrieval. If a C++ developer is losing a lot of time to data retrieval, they don’t know what they are doing.
The irony here is you are ranting about the wonders of value & reference semantics in these other languages in response to an essay highlighting the unfortunate shortcomings of the reference semantics in those languages.